I haven’t gotten very far with Harvester yet, having taken down the first cluster I built to re-purpose resources, but I thought I’d explore it again for running some VMS (security video recording) packages at a local business so we can avoid ESXi license costs and potentially scale-out (add servers) in the future without having to get even more licenses for vCenter and use up even more resources.
Harvester’s concept is super cool – set up Kubernetes infrastructure and use it for “legacy workloads” (aka VMs). Contrary to what a lot of other bloggers have written, Harvester does not run containers, so don’t get it twisted. That’s what Rancher is for. (side note: This misinformation got me running down a rabbit hole months ago when I stood up my first Harvester cluster thinking I was going to run a container for my TV recorder. I couldn’t figure out why there was no way to access the container layer, until finally I wrote the developers and they informed me there was no way to access it because it doesn’t exist.)
“Legacy workloads” are completely what we’d planned to run at this business anyway, so that’s just fine. Most decent VMS (video management systems) run in Windows, but we’d like to have some of the features only available via hypervisors, like cloning and testing new systems, or performing updates, without having to take the VM currently in production down or buy another physical machine. Harvester brings it to another level with the easy scale-out (adding more servers), and having cluster-awareness and high-availability embedded by design.
Of course, none of that matters if you can’t get your damn VMs to run, which is the first problem I ran into when I started the thing up. How do I get these clones of existing machines into the storage layer so I can create some new VMs around them?
Harvester only offers two options for creating an image:
- Provide a URL that responds to an HTTP GET request for a file that’s a consumable disk-image format (currently qcow2, raw/img or iso)
- Upload one of the aforementioned images via a web browser
I was pretty bummed these were the only options when I started out, as I had already connected a disk with my images to the host machine, thinking I could just copy the files from the disk to a particular location on the host filesystem. I should have probably RTFM, as this option (which is the most intuitive to me, but, alas) totally does not exist.
So I turned off the host and dug the NVMe with my images out, and popped it in a USB enclosure, thinking I’d use the upload option from my laptop. I watched the progress bar for long enough to know when to walk away – the file was 23GB, so I knew it should take a while – but the whole thing left me feeling uneasy that the process wouldn’t work. Sure enough, when I returned to the upload page, there was a “context cancelled” error. I tried it two more times, but Harvester kept thinking I had cancelled the upload at 99% finished. I am fairly certain I encountered a bug, but no time to file an issue, I’ve gotta see if this thing will even function for our workloads, and this wasn’t instilling me with the utmost confidence.
It seems like the “URL” option for providing disk images is the more mature of the two options, so I thought I’d look into running a local web server that would respond to a GET request with my image files. This turned out to be super easy, as basically every computer has or can get a copy of python without any trouble. Python has a built-in web server that simply provides whatever files are in the same directory in which it’s run by responding to GET requests and serving them up.
If you’ve got python installed, try it out. On my “server” machine, which in my case was my laptop, I had to do a few things to get it ready. Namely, make sure port 80 was open in my firewall, and make sure I was using the correct zone on my WIFI connection (for the port I had just opened) – I’m on Fedora 37, so if you’re using another OS, you should probably read this instead:
# check current connection:
nmcli con show
NAME UUID TYPE DEVICE
rabbit_hole e130190c-0c3b-4e22-8dc3-ebedc31a7d75 wifi wlp58s0
EastsideBigTom a51d9139-89bf-4a4f-9cad-25aaf3a8a2b0 wifi --
lan on the run 83afc4e0-a0bb-4b62-9437-59478a523da9 wifi --
Wired connection 1 eadbe5cc-ad09-4e43-8ad1-b24412a8610e ethernet --
# check to see if current connection is configured for a zone:
nmcli con show rabbit_hole | grep zone
connection.zone: --
# assign a zone to the current connection since it's not configured:
sudo nmcli con mod rabbit_hole connection.zone home
# make sure it worked:
nmcli con show rabbit_hole | grep zone
connection.zone: home
# open the port in the firewall - you can use any number up to 65536, but I chose 80 so I wouldn't have to use the port notation:
sudo firewall-cmd --zone=home --add-port=80/tcp --permanent
sudo firewall-cmd --reloadIf you are OK with this hole being open in your firewall indefinitely, use the --permanent flag for firewall-cmd, otherwise leave it out, and once your firewall is restarted it should be closed.
Now I set up a very rudimentary test to make sure the web server is responding to GET requests, since the machine will respond to a ping, but that’s not very helpful, considering ICMP is a completely different protocol than HTTP:
### on "server" machine (aka laptop, etc.) ###
# navigate to the folder with the files you want to send to Harvester:
cd /path/to/disk/images/you/are/going/to/transfer
# put some gibberish in a file to be served up on a GET request:
echo 'server working' > index.html
# start the actual http server (needs root privileges to attach to socket):
sudo python -m http.server 80
### in Harvester node console ###
# make GET request to "server" for the test gibberish file you created:
curl http://10.0.0.207/index.htmlYou should see the words “server working” in your Harvester console. If it didn’t work, make sure you spelled everything right, etc. If you don’t know the IP address of your “server”, you can run ip a in your console and it’ll let you know. If you’re not sure which network you’re on, you should probably get a new hobby.
Anyway, now go back to the image menu in Harvester’s web UI, and provide the ip address of your “server” to create images from your files on your node. Make sure you spell everything properly, including using eXaCt SaMe CaSe. Unlike Google, Harvester won’t figure out what you meant if there’s tyops.
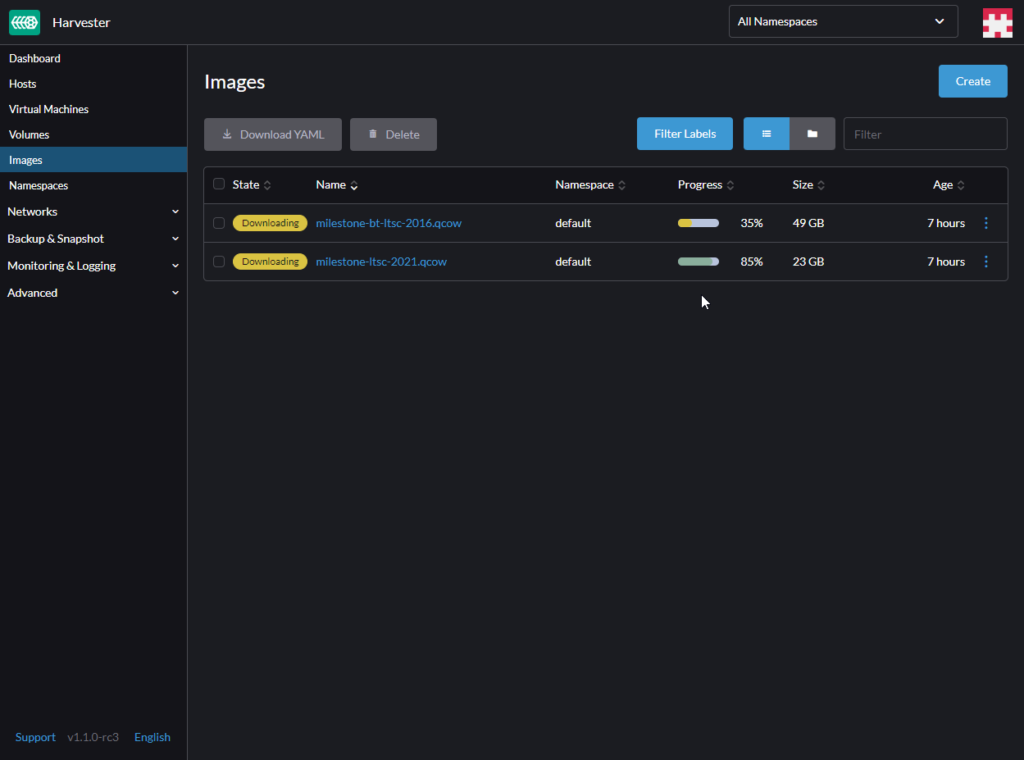
This method has proven far more reliable (well, in my case, actually worked) than trying to upload a local file, which is kind of hilarious given it is still uploading the files from the same machine (go figure). Providing files from a local URL also lets you queue a bunch of them to send at once, a definite time-saver. The upload function has an ominous warning not to leave the page or refresh your browser, so in this case you can navigate away from the page without fear of trashing (and painfully re-initiating) your arduously instigated multi-GB transfer process.
Give it a shot!