Quick little command line kung fu job with this parser called column
column -h
Usage:
column [options] [<file>...]
Columnate lists.
Options:
-t, --table create a table
-n, --table-name <name> table name for JSON output
-O, --table-order <columns> specify order of output columns
-C, --table-column <properties> define column
-N, --table-columns <names> comma separated columns names
-l, --table-columns-limit <num> maximal number of input columns
-E, --table-noextreme <columns> don't count long text from the columns to column width
-d, --table-noheadings don't print header
-m, --table-maxout fill all available space
-e, --table-header-repeat repeat header for each page
-H, --table-hide <columns> don't print the columns
-R, --table-right <columns> right align text in these columns
-T, --table-truncate <columns> truncate text in the columns when necessary
-W, --table-wrap <columns> wrap text in the columns when necessary
-L, --keep-empty-lines don't ignore empty lines
-J, --json use JSON output format for table
-r, --tree <column> column to use tree-like output for the table
-i, --tree-id <column> line ID to specify child-parent relation
-p, --tree-parent <column> parent to specify child-parent relation
-c, --output-width <width> width of output in number of characters
-o, --output-separator <string> columns separator for table output (default is two spaces)
-s, --separator <string> possible table delimiters
-x, --fillrows fill rows before columns
-h, --help display this help
-V, --version display version
For more details see column(1).
It’s in the util-linux package, which, if I am remembering correctly, is included by default in basically any release outside of netboot and cloud images
❯ pacman -Qi util-linux
Name : util-linux
Version : 2.40.1-1
Description : Miscellaneous system utilities for Linux
Architecture : x86_64
URL : https://github.com/util-linux/util-linux
Licenses : BSD-2-Clause BSD-3-Clause BSD-4-Clause-UC GPL-2.0-only
GPL-2.0-or-later GPL-3.0-or-later ISC LGPL-2.1-or-later
LicenseRef-PublicDomain
Groups : None
Provides : rfkill hardlink
Depends On : util-linux-libs=2.40.1 coreutils file libmagic.so=1-64
glibc libcap-ng libxcrypt libcrypt.so=2-64 ncurses
libncursesw.so=6-64 pam readline shadow systemd-libs
libsystemd.so=0-64 libudev.so=1-64 zlib
Optional Deps : words: default dictionary for look
Required By : apr arch-install-scripts base devtools dracut f2fs-tools
fakeroot inxi jfsutils keycloak libewf nilfs-utils
ntfsprogs-ntfs3 nvme-cli ostree quickemu reiserfsprogs
sbctl systemd zeromq
Optional For : e2fsprogs gzip syslinux
Conflicts With : rfkill hardlink
Replaces : rfkill hardlink
Installed Size : 14.47 MiB
Packager : Christian Hesse <[email protected]g>
Build Date : Mon 06 May 2024 12:22:23 PM PDT
Install Date : Wed 08 May 2024 09:27:41 AM PDT
Install Reason : Installed as a dependency for another package
Install Script : No
Validated By : Signature
this demonstrates why it’s included: It’s required by basically all of the setup infrastructure packages (makes sense). But I don’t really see column getting a lot of attention. Not sure why.
Here I used it to convert a list of installed flatpak containers to both JSON and YAML, using the column names from the flatpak’s output options (see flatpak list --help for available columns).
Start by making a list using the flatpak list --columns=$COLUMNS command:
# export comma-separated column headers, in desired order
export COLUMNS='name,application,version,branch,arch,origin,installation,ref'
# make a list of flatpaks with these columns
flatpak list --app --columns=$NAMES > all-flatpak-apps.list
# verify the list was created
cat all-flatpak-apps.list
# output (truncated):
Delta Chat chat.delta.desktop v1.44.1 stable x86_64 flathub user chat.delta.desktop/x86_64/stable
Twilio Authy com.authy.Authy 2.5.0 stable x86_64 flathub user com.authy.Authy/x86_64/stable
Discord com.discordapp.Discord 0.0.54 stable x86_64 flathub user com.discordapp.Discord/x86_64/stable
GitButler com.gitbutler.gitbutler 0.11.7 stable x86_64 flathub user com.gitbutler.gitbutler/x86_64/stable
Drawing com.github.maoschanz.drawing 1.0.2 stable x86_64 flathub user com.github.maoschanz.drawing/x86_64/stable
Flatseal com.github.tchx84.Flatseal 2.2.0 stable x86_64 flathub user com.github.tchx84.Flatseal/x86_64/stable
Extension Manager com.mattjakeman.ExtensionManager 0.5.1 stable x86_64 flathub user com.mattjakeman.ExtensionManager/x86_64/stable
Yubico Authenticator com.yubico.yubioath 7.0.0 stable x86_64 flathub user com.yubico.yubioath/x86_64/stable
. . .
It’s kinda hard to read like that, but I suppose if your font were small enough, or the terminal wide enough, the lines would stop wrapping and they’d be easier to read…
Then, take the list and convert it to json with a little column parsing:
# the flags are:
# 1. create a table (-t),
# 2. give it these headers (-N $comma,separated,headervals)
# 3. limit it to the number we gave you (-l $integer)
# 4. make it json! (-J)
# 5. $INPUT_FILE > [$OUTPUT_FILE]
column -t -d -N $NAMES -l 8 -J all-flatpak-apps.list > flatpak-apps.json
# column is a lot more forgiving of formatting than jq and yqI haven’t had a lot of luck piping to column directly to make a parse-inception one-liner, which is why I am making two files (the flatpak.list and the .json file). I am sure there’s some people out there who could make this work, but I want to keep it on the less complicated side for demonstrative purposes, as well.
The output will be json format with the column parse by itself, but some of us like to pretty-print our json with jq , since the colors make it easier to read – especially when they’re not even pretty-printed:
column -t -d -N $NAMES -l 8 -J all-flatpak-apps.list | jq
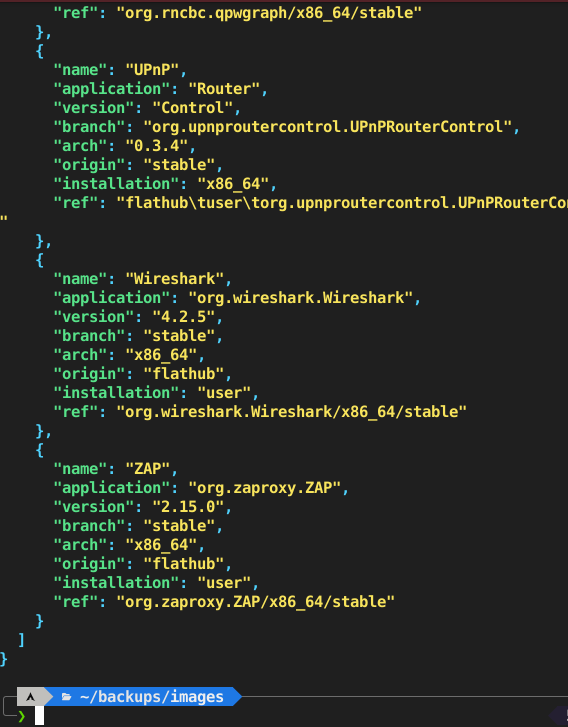
{
"table": [
{
"name": "Delta",
"application": "Chat",
"version": "chat.delta.desktop",
"branch": "v1.44.1",
"arch": "stable",
"origin": "x86_64",
"installation": "flathub",
"ref": "user\tchat.delta.desktop/x86_64/stable"
},
{
"name": "Twilio",
"application": "Authy",
"version": "com.authy.Authy",
"branch": "2.5.0",
"arch": "stable",
"origin": "x86_64",
"installation": "flathub",
"ref": "user\tcom.authy.Authy/x86_64/stable"
},
{
"name": "UPnP",
"application": "Router",
"version": "Control",
"branch": "org.upnproutercontrol.UPnPRouterControl",
"arch": "0.3.4",
"origin": "stable",
"installation": "x86_64",
"ref": "flathub\tuser\torg.upnproutercontrol.UPnPRouterControl/x86_64/stable"
},
{
"name": "Wireshark",
"application": "org.wireshark.Wireshark",
"version": "4.2.5",
"branch": "stable",
"arch": "x86_64",
"origin": "flathub",
"installation": "user",
"ref": "org.wireshark.Wireshark/x86_64/stable"
},
{
"name": "ZAP",
"application": "org.zaproxy.ZAP",
"version": "2.15.0",
"branch": "stable",
"arch": "x86_64",
"origin": "flathub",
"installation": "user",
"ref": "org.zaproxy.ZAP/x86_64/stable"
}
]
}
And if you need yaml, the same thing works with yq:
# what NOT to do (if you want to be able to read it):
column -t -d -N $NAMES -l 8 -J all-flatpak-apps.list | yq
{"table": [{"name": "Delta", "application": "Chat", "version": "chat.delta.desktop", "branch": "v1.44.1", "arch": "stable", "origin": "x86_64", "installation": "flathub", "ref": "user\tchat.delta.desktop/x86_64/stable"}, {"name": "Twilio", "application": "Authy", . . .
# sometimes yq requires being super-explicit:
# yq flags are:
# 1. input file type (-p type)
# 2. output file type (-o type)
# 3. pretty-print (-P)
column -t -d -N $NAMES -l 8 -J all-flatpak-apps.list | yq -p json -o yaml -P
table:
- name: Delta
application: Chat
version: chat.delta.desktop
branch: v1.44.1
arch: stable
origin: x86_64
installation: flathub
ref: "user\tchat.delta.desktop/x86_64/stable"
- name: Twilio
application: Authy
version: com.authy.Authy
branch: 2.5.0
arch: stable
origin: x86_64
installation: flathub
ref: "user\tcom.authy.Authy/x86_64/stable"
- name: Discord
application: com.discordapp.Discord
version: 0.0.54
branch: stable
arch: x86_64
origin: flathub
installation: user
ref: com.discordapp.Discord/x86_64/stable
. . . I’ve got the go-yq package, which has a much newer version of jq included with it, so if you’re seeing some differences in behavior or command-line arguments, that could be why – give it a shot if you’re having issues. (I do prefer the original jq, but I don’t really have a choice since it’s a dependency of devtools…
# not a huge fan of gojq-bin, but go-yq is awesome...
❯ pacman -Qi go-yq
Name : go-yq
Version : 4.44.1-1
Description : Portable command-line YAML processor
Architecture : x86_64
URL : https://github.com/mikefarah/yq
Licenses : MIT
Groups : None
Provides : None
Depends On : glibc
Optional Deps : None
Required By : None
Optional For : None
Conflicts With : yq
Replaces : None
Installed Size : 9.58 MiB
Packager : Daniel M. Capella <[email protected]g>
Build Date : Sat 11 May 2024 08:14:21 PM PDT
Install Date : Sat 11 May 2024 09:08:38 PM PDT
Install Reason : Explicitly installed
Install Script : No
Validated By : Signature
And don’t forget, column should be able to format basically any time of list with repeating columns. I guess that’s all for now, enjoy!
ok nevermind, just one more thing: This has nothing to do with column, necessarily, but it’s all the output you can get when you choose json as your output. I’ll have to do another post about this, but it’s tangentially related.
Look at the output from kubernetes kubectl get pods -A :
kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
default elasticsearch-coordinating-0 1/1 Running 0 91m
default elasticsearch-coordinating-1 1/1 Running 0 91m
default elasticsearch-data-0 1/1 Running 0 91m
default elasticsearch-data-1 1/1 Running 0 91m
default elasticsearch-ingest-0 1/1 Running 0 91m
default elasticsearch-ingest-1 1/1 Running 0 91m
default elasticsearch-master-0 1/1 Running 0 91m
default elasticsearch-master-1 1/1 Running 0 91m
kube-system coredns-7db6d8ff4d-x8nnb 1/1 Running 1 (101m ago) 125m
kube-system etcd-minikube 1/1 Running 1 (101m ago) 125m
kube-system kube-apiserver-minikube 1/1 Running 1 (101m ago) 125m
kube-system kube-controller-manager-minikube 1/1 Running 1 (101m ago) 125m
kube-system kube-proxy-jbds4 1/1 Running 1 (101m ago) 125m
kube-system kube-scheduler-minikube 1/1 Running 1 (101m ago) 125m
kube-system metrics-server-c59844bb4-d8wnd 1/1 Running 1 (101m ago) 119m
kube-system storage-provisioner 1/1 Running 3 (101m ago) 125m
kubernetes-dashboard dashboard-metrics-scraper-b5fc48f67-j5znq 1/1 Running 1 (101m ago) 121m
kubernetes-dashboard kubernetes-dashboard-779776cb65-rh8s2 1/1 Running 2 (101m ago) 121m
portainer portainer-7bf545c674-xnjjr 1/1 Running 1 (101m ago) 119m
yakd-dashboard yakd-dashboard-5ddbf7d777-mzqk2 1/1 Running 1 (101m ago) 119m
It’s not bad, but check out all the info you get when you add --output json:
# +`jq` to colorize the output (or `yq -p json -o json -P`)
kubectl get pods -A -o json | jq
{
"apiVersion": "v1",
"items": [
{
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"creationTimestamp": "2024-05-25T12:26:56Z",
"generateName": "elasticsearch-coordinating-",
"labels": {
"app": "coordinating-only",
"app.kubernetes.io/component": "coordinating-only",
"app.kubernetes.io/instance": "elasticsearch",
"app.kubernetes.io/managed-by": "Helm",
"app.kubernetes.io/name": "elasticsearch",
"app.kubernetes.io/version": "8.13.4",
"apps.kubernetes.io/pod-index": "0",
"controller-revision-hash": "elasticsearch-coordinating-64759546b",
"helm.sh/chart": "elasticsearch-21.1.0",
"statefulset.kubernetes.io/pod-name": "elasticsearch-coordinating-0"
},
"name": "elasticsearch-coordinating-0",
"namespace": "default",
"ownerReferences": [
{
"apiVersion": "apps/v1",
"blockOwnerDeletion": true,
"controller": true,
"kind": "StatefulSet",
"name": "elasticsearch-coordinating",
"uid": "e403f4a1-3058-4830-8f4e-25323fa68be5"
}
],
"resourceVersion": "2737",
"uid": "5c26ea5d-5ec7-40b1-946c-573651123552"
},
"spec": {
"affinity": {},
"automountServiceAccountToken": false,
"containers": [
{
"env": [
{
"name": "MY_POD_NAME",
"valueFrom": {
"fieldRef": {
"apiVersion": "v1",
"fieldPath": "metadata.name"
}
}
},
{
"name": "BITNAMI_DEBUG",
"value": "false"
},
{
"name": "ELASTICSEARCH_CLUSTER_NAME",
"value": "elastic"
},
{
"name": "ELASTICSEARCH_IS_DEDICATED_NODE",
"value": "yes"
},
{
"name": "ELASTICSEARCH_NODE_ROLES"
},
{
"name": "ELASTICSEARCH_TRANSPORT_PORT_NUMBER",
"value": "9300"
},
{
"name": "ELASTICSEARCH_HTTP_PORT_NUMBER",
"value": "9200"
},
{
"name": "ELASTICSEARCH_CLUSTER_HOSTS",
"value": "elasticsearch-master-hl.default.svc.cluster.local,elasticsearch-coordinating-hl.default.svc.cluster.local,elasticsearch-data-hl.default.svc.cluster.local,elasticsearch-ingest-hl.default.svc.cluster.local,"
},
{
"name": "ELASTICSEARCH_TOTAL_NODES",
. . . It’s nice that kubectl actually has a yaml output, since it’s a little easier to read than json, what with all the [{"punctuation": "on"},{"basically": "every}, {"word": true}], but most programs, if they even offer json, probably aren’t going to offer yaml – so to convert it, here’s the pipe string:
# adding `yq` colorizes output to `yaml` output, too
kubectl get pods -A -o json | yq -p json -o yaml -P
apiVersion: v1
items:
- apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2024-05-25T12:26:56Z"
generateName: elasticsearch-coordinating-
labels:
app: coordinating-only
app.kubernetes.io/component: coordinating-only
app.kubernetes.io/instance: elasticsearch
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: elasticsearch
app.kubernetes.io/version: 8.13.4
apps.kubernetes.io/pod-index: "0"
controller-revision-hash: elasticsearch-coordinating-64759546b
helm.sh/chart: elasticsearch-21.1.0
statefulset.kubernetes.io/pod-name: elasticsearch-coordinating-0
name: elasticsearch-coordinating-0
namespace: default
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: StatefulSet
name: elasticsearch-coordinating
uid: e403f4a1-3058-4830-8f4e-25323fa68be5
resourceVersion: "2737"
uid: 5c26ea5d-5ec7-40b1-946c-573651123552
spec:
affinity: {}
automountServiceAccountToken: false
containers:
- env:
- name: MY_POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: BITNAMI_DEBUG
value: "false"
- name: ELASTICSEARCH_CLUSTER_NAME
value: elastic
- name: ELASTICSEARCH_IS_DEDICATED_NODE
value: "yes"
- name: ELASTICSEARCH_NODE_ROLES
- name: ELASTICSEARCH_TRANSPORT_PORT_NUMBER
value: "9300"
- name: ELASTICSEARCH_HTTP_PORT_NUMBER
value: "9200"
- name: ELASTICSEARCH_CLUSTER_HOSTS
value: elasticsearch-master-hl.default.svc.cluster.local,elasticsearch-coordinating-hl.default.svc.cluster.local,elasticsearch-data-hl.default.svc.cluster.local,elasticsearch-ingest-hl.default.svc.cluster.local,
- name: ELASTICSEARCH_TOTAL_NODES
value: "4"
- name: ELASTICSEARCH_CLUSTER_MASTER_HOSTS
value: elasticsearch-master-0 elasticsearch-master-1
- name: ELASTICSEARCH_MINIMUM_MASTER_NODES
value: "2"
- name: ELASTICSEARCH_ADVERTISED_HOSTNAME
value: $(MY_POD_NAME).elasticsearch-coordinating-hl.default.svc.cluster.local
- name: ELASTICSEARCH_HEAP_SIZE
value: 128m
image: docker.io/bitnami/elasticsearch:8.13.4-debian-12-r0
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 5
initialDelaySeconds: 180
periodSeconds: 10
successThreshold: 1
tcpSocket:
port: rest-api
timeoutSeconds: 5
name: elasticsearch
ports:
- containerPort: 9200
name: rest-api
protocol: TCP
- containerPort: 9300
name: transport
protocol: TCP
readinessProbe:
exec:
command:
- /opt/bitnami/scripts/elasticsearch/healthcheck.sh
failureThreshold: 5
initialDelaySeconds: 90
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5
resources:
limits:
cpu: 750m
ephemeral-storage: 1Gi
memory: 768Mi
requests:
cpu: 500m
ephemeral-storage: 50Mi
memory: 512Mi
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
privileged: false
readOnlyRootFilesystem: true
runAsGroup: 1001
runAsNonRoot: true
runAsUser: 1001
seLinuxOptions: {}
seccompProfile:
type: RuntimeDefault
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /tmp
name: empty-dir
subPath: tmp-dir
- mountPath: /opt/bitnami/elasticsearch/config
name: empty-dir
subPath: app-conf-dir
. . .
It sure is nice to be able to read the stuff that comes out of the tools we’re using every day…