-
Arch Linux for Windows: Now available from the Microsoft Store

Does anyone else sense the irony? Yes, Arch Linux is available from the Microsoft Store, and no, I’m not kidding. Go ahead and see for yourself: https://apps.microsoft.com/detail/9mznmnksm73x?hl=en-us&gl=US My immediate reaction when I saw this was, “woah, really?”, “that’s crazy”, and, “I never thought I’d see this day”, and I wonder if it’s as jarring to…
-
Using `grep` to focus only on that which is important

This is a little beginner command-line demonstration for finding the results you need most. A lot of the time in the command line, a simple ls can return way more than any one person can reasonably deal with. Most people know how to use ls with extension flags: ls *.sh ; ls -a ; ls…
-
Outputting a list of variables to `json` or `yaml` using `column` and `goyq`
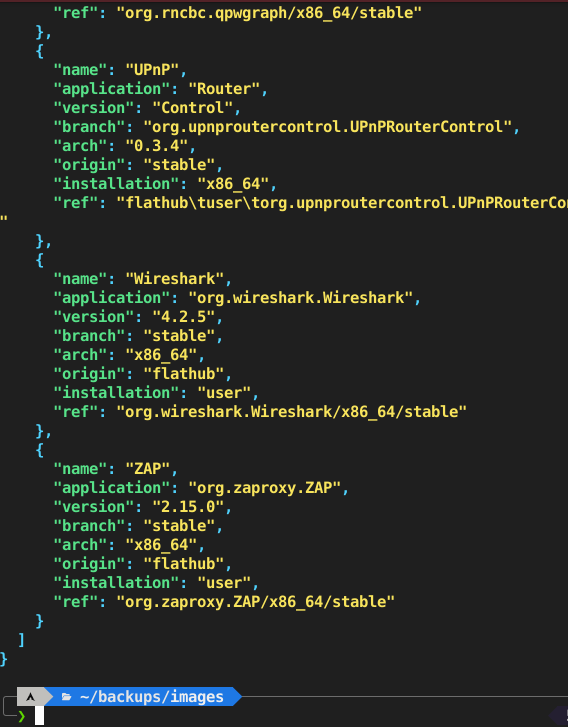
Quick little command line kung fu job with this parser called column It’s in the util-linux package, which, if I am remembering correctly, is included by default in basically any release outside of netboot and cloud images this demonstrates why it’s included: It’s required by basically all of the setup infrastructure packages (makes sense). But…
-
Using `obs` CLI controller with my new favorite mind-mapping software Obsidian – in a flatpak container
There’s always issues here or there trying to incorporate container apps with the desktop, due to their sandboxed nature and subsequent lack of out-of-the-box feature parity with their distro-packaged and supported counterparts. This is not a post about how awesome Obsidian is, but if you haven’t heard of it, I recommend checking it out: https://obsidian.md/…
-
`rmw` – the trash-aware `rm` your CLI probably should’ve had by default

Hasn’t everybody deleted some stuff in the command line, wishing they had a way to get it back? Well, by default there are no do-overs. That’s where rmw comes in: rmw creates a trash can for your command line, so even after you delete some files (as long as you use it), you should be…