-
Celebrate your Annual `Octocat Day`?
Octocat Birthday celebration site unsurprisingly located on… wait for it… GitHub Pages: https://nomangul.github.io/octocat-day/ I thought this was so cute, I thought I’d put it up real quick. I found it while wondering in earnest when I had signed up for GitHub. Turns out it was a lot earlier than I remembered – not that I’ve…
-
Have I really not written about `rsync`?

There’s lots of great backup tools out there – borg, rdiffbackup, bareos, zfs and btrfs send/receive, pvesync, etc. and the cutest mascotted backup program ever, of course, pikabackup (it’s adorable!) all with their own traits and best-practice use cases. I have to say, though, call me DIY, a glutton for punishment, or just plain nerdy,…
-
Benefactors, Meet Cartography: Using Public Disclosure Data for a Geospatial Graph with Python, Pandas, GeoPandas and Matplotlib
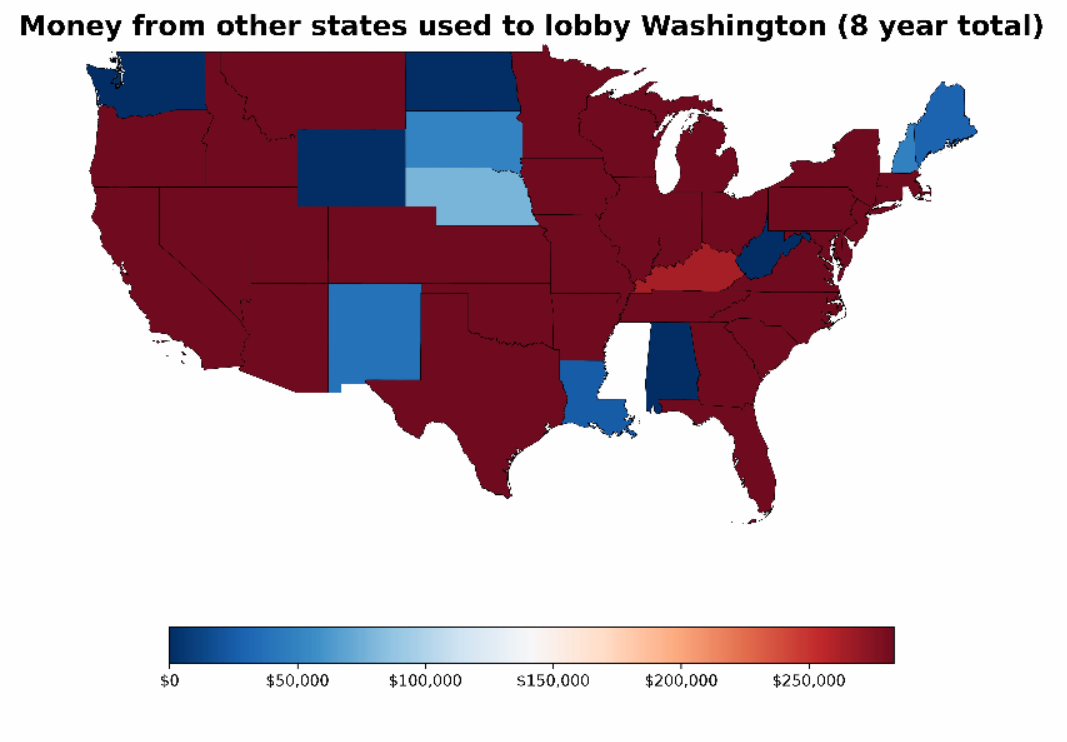
I was looking at datasets on data.wa.gov to see what might be fun for a project, and I came across public info disclosing the amount paid to employ WA state lobbyists. It’s a very localized representation of interests attempting to influence politics and policy for our residents and lawmakers, as it represents money spent only…