-
Running an Arch Linux Router for About a Year

So, I wasn’t so sure how soon I should write about this, but I have a fiber connection here in Seattle I’m pretty excited about. For the past decade I’d been living in Olympia, WA, where Comcast is the only game in town, and upload speeds are hampered by only having 4 channels across cable…
-
Quick On-The-Fly Batch Processing Using `for` Loop in `cmd` (Windows)

I thought I’d throw this up real quick, because I am constantly using for loops in bash during normal command traversal, but I am not as familiar about how to do them in Windows – off the top, I can recall cmd has for loops, they omit done, use parens and % in place of…
-
Physical to Virtual Machine Conversion with Virt-Manager Using Thin Volumes for Each VM (aka `Proxmox Style` NoCoW)
I love Proxmox, but I’ve always preferred to have a more modular style. There’s a lot to be said about ‘batteries included’ hypervisors with all the bells and whistles all set up for you automatically. But what if you want to use other elements of another hypervisor with them not meant for them specifically? Often…
-
(very) Unscientific ZFS vs XFS + Thin LVM Benchmarks
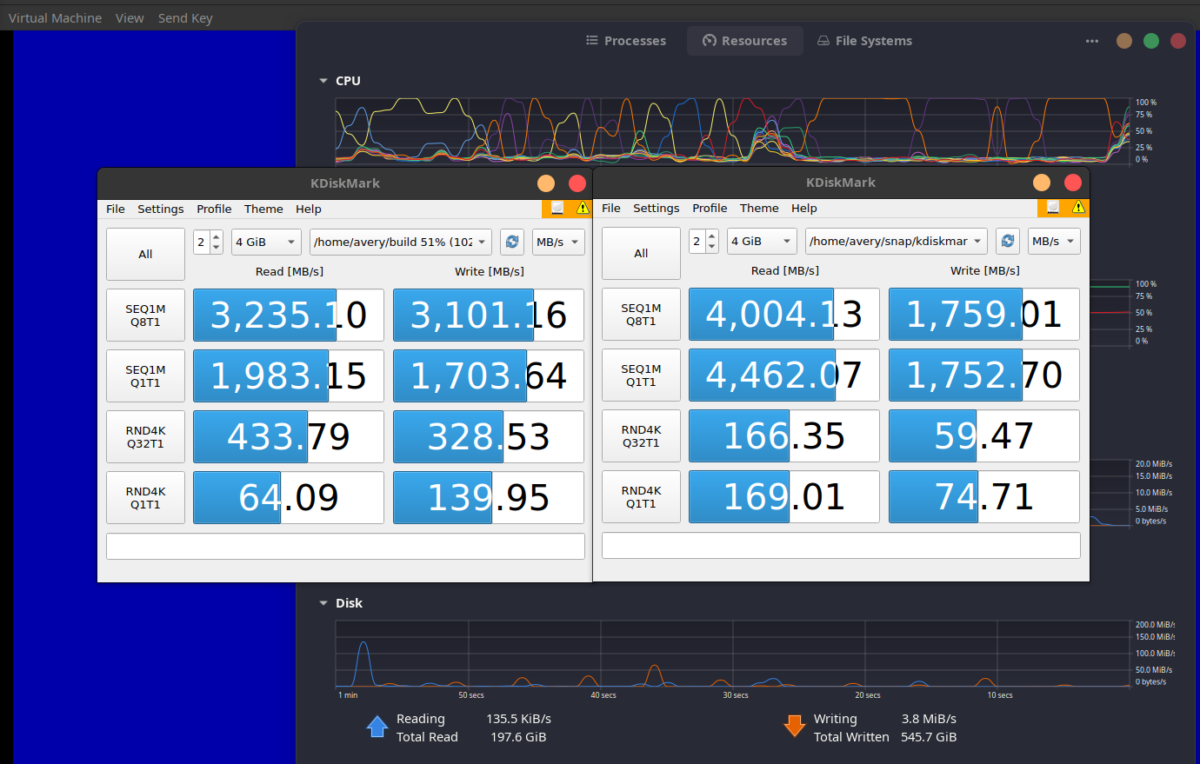
I found this screenshot from a couple days ago, but it illustrates something I’ve known subjectively for a long time now: ZFS is the mother of all sequential read filesystems, but it’s quite a bit “slower” than other common filesystems (especially non-cow). That’s mainly because Linux uses a boatload of tiny files necessary to be…
-
Celebrate your Annual `Octocat Day`?
Octocat Birthday celebration site unsurprisingly located on… wait for it… GitHub Pages: https://nomangul.github.io/octocat-day/ I thought this was so cute, I thought I’d put it up real quick. I found it while wondering in earnest when I had signed up for GitHub. Turns out it was a lot earlier than I remembered – not that I’ve…
-
Have I really not written about `rsync`?

There’s lots of great backup tools out there – borg, rdiffbackup, bareos, zfs and btrfs send/receive, pvesync, etc. and the cutest mascotted backup program ever, of course, pikabackup (it’s adorable!) all with their own traits and best-practice use cases. I have to say, though, call me DIY, a glutton for punishment, or just plain nerdy,…
-
Benefactors, Meet Cartography: Using Public Disclosure Data for a Geospatial Graph with Python, Pandas, GeoPandas and Matplotlib
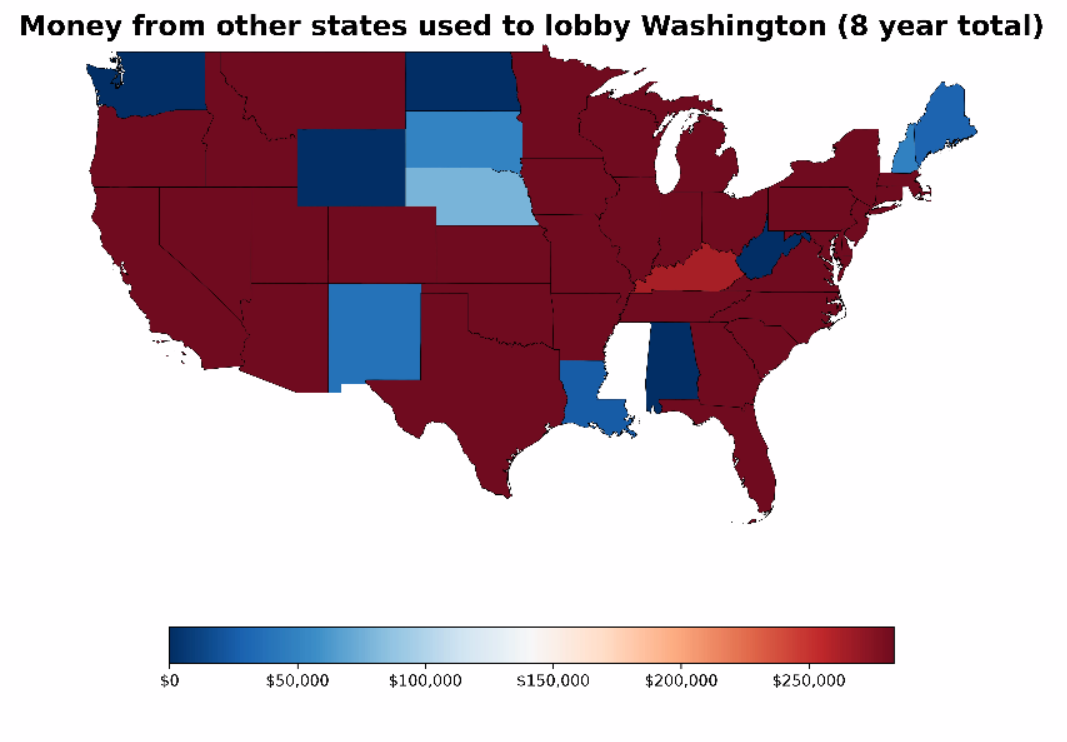
I was looking at datasets on data.wa.gov to see what might be fun for a project, and I came across public info disclosing the amount paid to employ WA state lobbyists. It’s a very localized representation of interests attempting to influence politics and policy for our residents and lawmakers, as it represents money spent only…
-
Arch Linux for Windows: Now available from the Microsoft Store

Does anyone else sense the irony? Yes, Arch Linux is available from the Microsoft Store, and no, I’m not kidding. Go ahead and see for yourself: https://apps.microsoft.com/detail/9mznmnksm73x?hl=en-us&gl=US My immediate reaction when I saw this was, “woah, really?”, “that’s crazy”, and, “I never thought I’d see this day”, and I wonder if it’s as jarring to…
-
Using `grep` to focus only on that which is important

This is a little beginner command-line demonstration for finding the results you need most. A lot of the time in the command line, a simple ls can return way more than any one person can reasonably deal with. Most people know how to use ls with extension flags: ls *.sh ; ls -a ; ls…
-
Outputting a list of variables to `json` or `yaml` using `column` and `goyq`
Quick little command line kung fu job with this parser called column It’s in the util-linux package, which, if I am remembering correctly, is included by default in basically any release outside of netboot and cloud images this demonstrates why it’s included: It’s required by basically all of the setup infrastructure packages (makes sense). But…